~90% fewer tokens
Exposes 3 meta-tools instead of hundreds, so your agent's context stays flat no matter how many servers you add. Measured: 97% less tool overhead per request, ~90% fewer tokens, same task success.
It's not the model. Every server dumps its entire tool list into your agent's context on every request, ~24k tokens of definitions before you've typed a word. Conduit puts them behind one local gateway that exposes 3 meta-tools the agent searches on demand. Measured: 97% less tool overhead per request, ~90% fewer tokens, same results. Local-first, keys in your OS keychain.
free & open source · Windows, macOS & Linux

works with Claude · Cursor · VS Code · Windsurf · Codex · Antigravity
Tool definitions, counted in tokens, before you've typed a word.
97% less per request · ~90% fewer tokens overall · same task success · see the benchmark
Exposes 3 meta-tools instead of hundreds, so your agent's context stays flat no matter how many servers you add. Measured: 97% less tool overhead per request, ~90% fewer tokens, same task success.
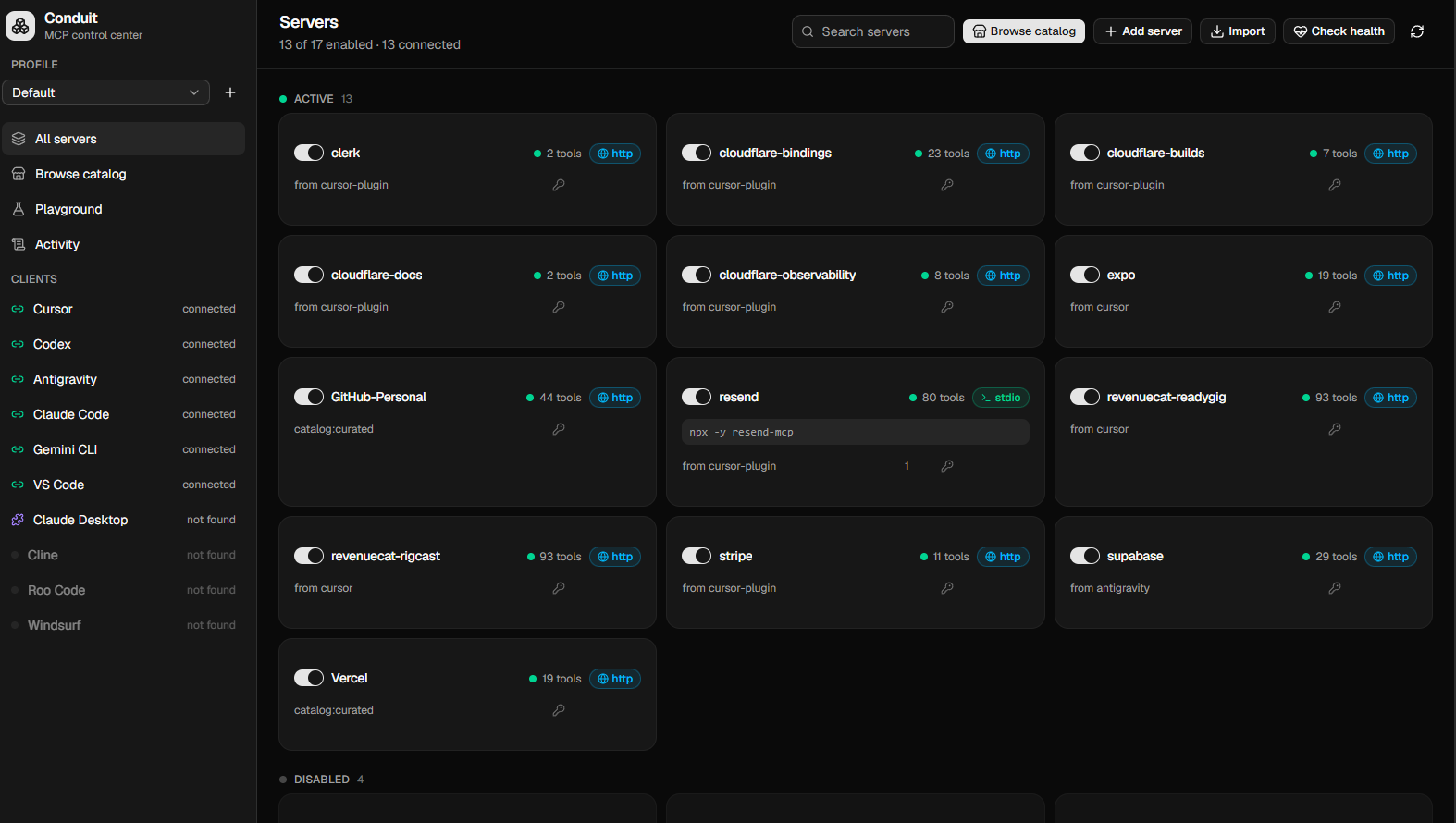
Point each AI tool at Conduit once. It fans out to every server you manage, with hot toggles and no restarts.
API keys live in your OS keychain, injected at runtime. Never in a client config, never in the cloud.
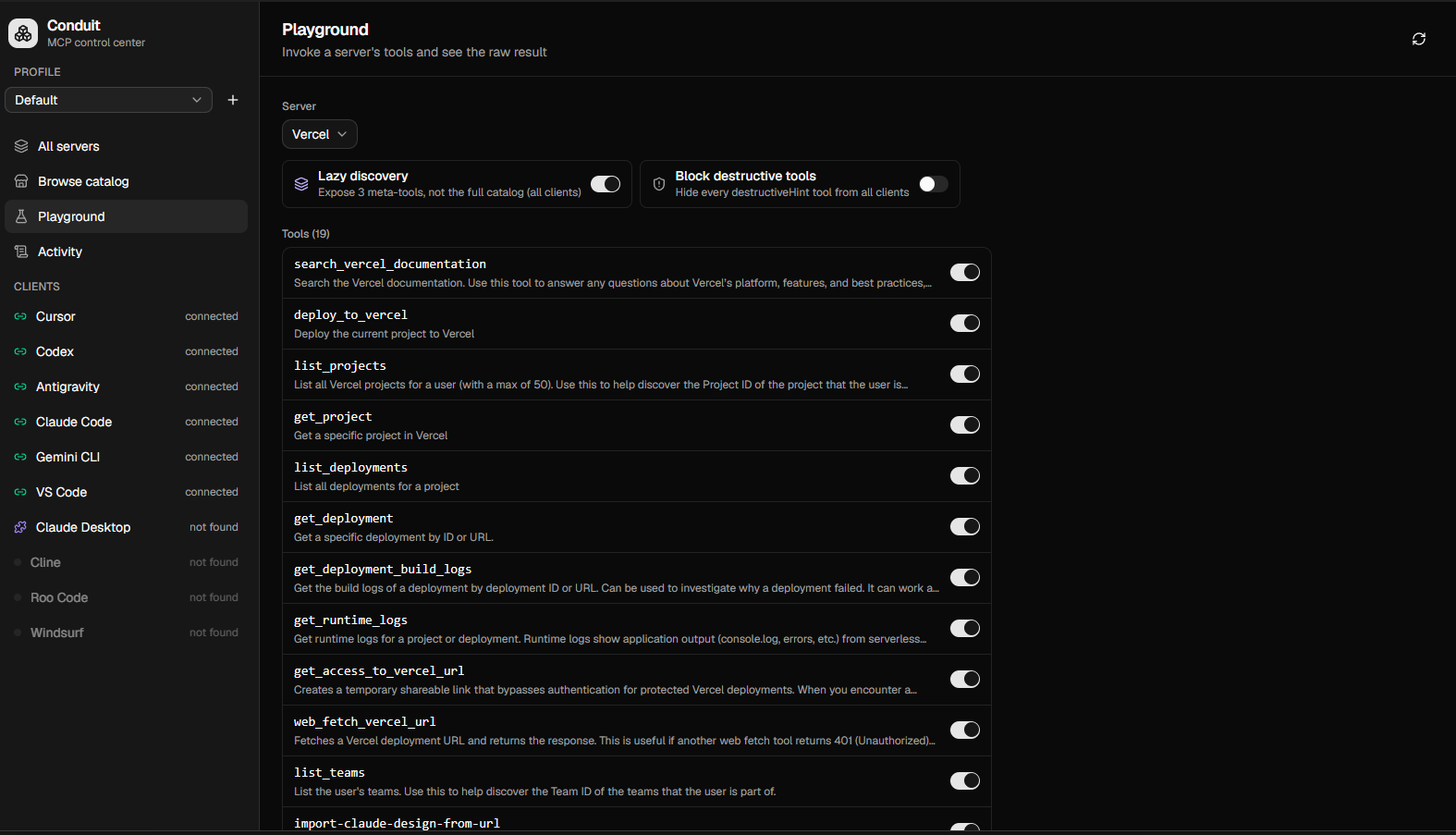
Toggle any tool on or off. One switch hides every destructive tool from every client, fleet-wide.
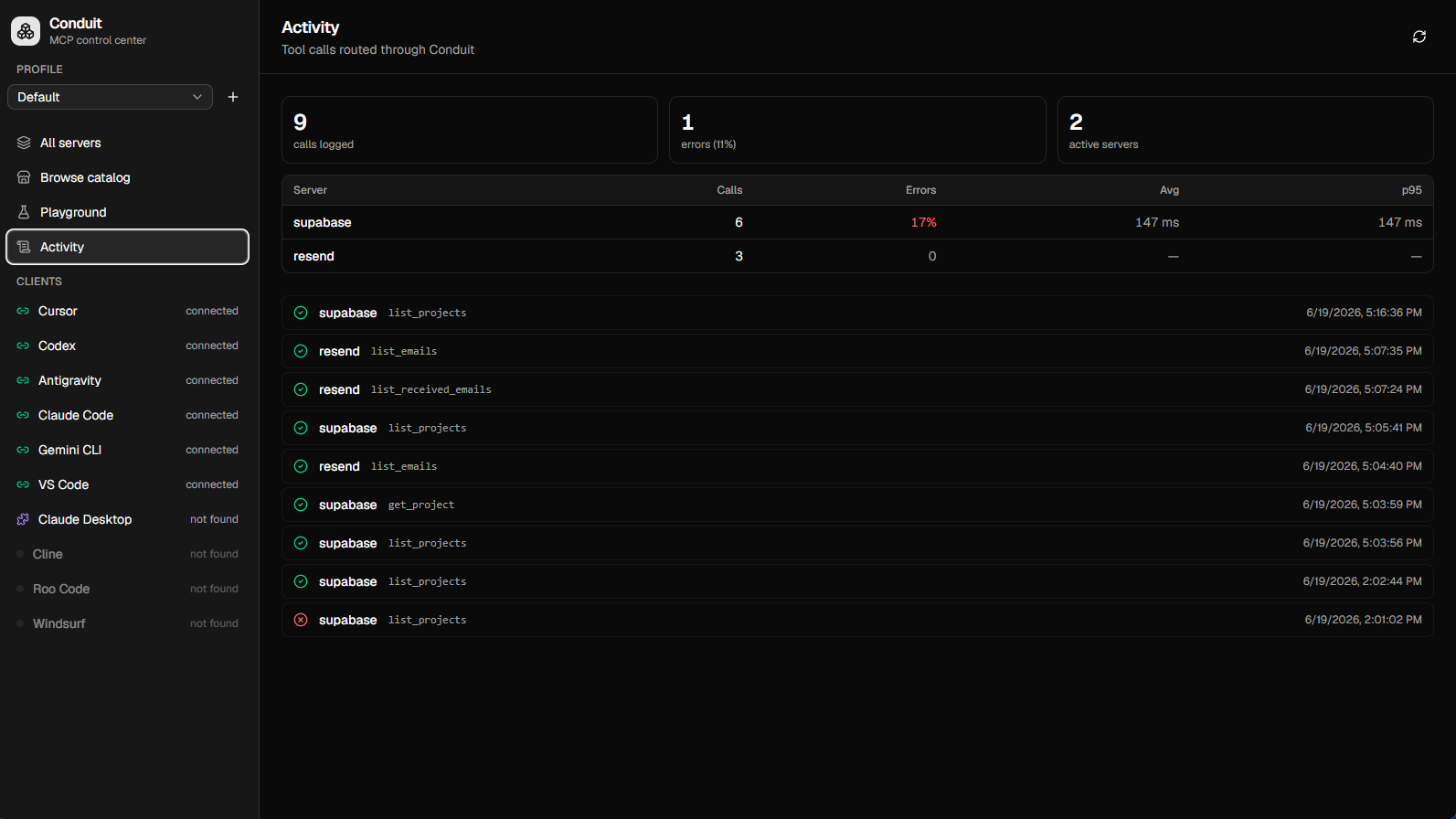
Per-server latency, error rates and a full audit trail of every tool call, built into the app.
A native desktop app. Runs local servers as host processes and proxies remote ones. Zero infrastructure.
a look inside
how it works
Hundreds of tools across your servers. Three in your agent's context.
Three meta-tools in context instead of hundreds, on every AI tool you already use.
Download Conduit